Kernel backups for Debian security updates
2 Jul 2014
Two of our most important machines, both running Debian Stable, failed to boot after a routine kernel security update. In both cases, the security update itself was not the cause of the boot failure, but merely triggered latent problems (for the full story, see below under The problem with the snapshot machine).
Also in both cases, it would have been a great help if we could have booted the old kernel/initrd. But by default, Debian does not keep backups of the kernel or initrd.
In Testing and Unstable, you might get a new kernel with a new package name; the old kernel/initrd belong to a different package from the new kernel/initrd, so they will coexist until the old package is removed. In a Stable security update however, the package name remains the same. You simply get a slightly higher version of the same package, replacing all the constituent files. If the new kernel image or initrd is unbootable for some reason, there’s no easy way to get the machine back up quickly.
We wrote a kernel pre-installation script that makes backups of the kernel/initrd, providing a safety net for these situations.
A typical Debian Wheezy machine
# dpkg -l linux-image-3.2.0-4-amd64
ii linux-image-3.2.0-4-amd64 3.2.54-2 amd64 Linux 3.2 for 64-bit PCs
# md5sum /boot/{vmlinuz,initrd}*
a9f3061e6770cd5127ee610f4ad8cd9c /boot/vmlinuz-3.2.0-4-amd64
64954138ae6ecd4fb6d595da19b828be /boot/initrd.img-3.2.0-4-amd64
# egrep '(vmlinuz|initrd)' /boot/grub/grub.cfg
linux /boot/vmlinuz-3.2.0-4-amd64 root=UUID=ff68c9e1-efea-4a2f-b011-f9d24a392b62 ro quiet
initrd /boot/initrd.img-3.2.0-4-amd64
(single user mode entries omitted)The kernel package is linux-image-3.2.0-4-amd64, version 3.2.54-2, and /boot contains just one kernel and initrd, both of which are in GRUB.
After a kernel update
# dpkg -l linux-image-3.2.0-4-amd64
ii linux-image-3.2.0-4-amd64 3.2.57-3+deb7u2 amd64 Linux 3.2 for 64-bit PCs
# md5sum /boot/{vmlinuz,initrd}*
f9d95fba346bc7d5c6a94400c5405d24 /boot/vmlinuz-3.2.0-4-amd64
e753f3984ac4897074749c94c42e6b34 /boot/initrd.img-3.2.0-4-amd64
# egrep '(vmlinuz|initrd)' /boot/grub/grub.cfg
linux /boot/vmlinuz-3.2.0-4-amd64 root=UUID=ff68c9e1-efea-4a2f-b011-f9d24a392b62 ro quiet
initrd /boot/initrd.img-3.2.0-4-amd64The kernel package has its version bumped to 3.2.57-3+deb7u2, and the kernel image and initrd in /boot have been completely replaced (see md5sums). If the new kernel image and/or initrd fail to boot, the machine is unbootable with manual assistance.
The fix: a kernel preinst script
Our fix for this problem is to automatically make backup copies of the kernel image and initrd files during the installation of the update.
These backups are picked up by GRUB and can be booted in case of an emergency.
The following shell script should be installed as /etc/kernel/preinst.d/local-backup:
#! /bin/sh
# Author: Marcel Moreaux; Copyright (c) 2014 Code Yellow B.V.
# MIT-licensed (feel free to use, share, and modify, but keep attribution).
set -e
# Number of kernel backups to keep (not counting the original)
BACKUPS="4"
DIR="/boot"
VERSION="$1"
DATE="$(date '+%Y%m%d%H%M')"
echo "Making backup of kernel/initrd..." > /dev/stderr
for F in "$DIR"/*-"$VERSION"
do
# Clean up oldest copies to make room
while [ $(ls "$F"* | wc -l) -gt "$BACKUPS" ]
do
O="$(ls ${F}~~* | sort | head -1)"
echo "Removing oldest backup: $O" > /dev/stderr
rm "$O"
done
# Make backup
B="${F}~~backup$DATE"
echo "Backup $F -> $B" > /dev/stderr
cp -f "$F" "$B"
doneAfter a kernel update, with backups
After performing the same kernel update as above with the preinst script in place, we see the following:
# dpkg -l linux-image-3.2.0-4-amd64
ii linux-image-3.2.0-4-amd64 3.2.57-3+deb7u2 amd64 Linux 3.2 for 64-bit PCs
# md5sum /boot/{vmlinuz,initrd}*
f9d95fba346bc7d5c6a94400c5405d24 /boot/vmlinuz-3.2.0-4-amd64
a9f3061e6770cd5127ee610f4ad8cd9c /boot/vmlinuz-3.2.0-4-amd64~~backup201407021638
ed74448bee73864dfa99f9d5781b98c6 /boot/initrd.img-3.2.0-4-amd64
64954138ae6ecd4fb6d595da19b828be /boot/initrd.img-3.2.0-4-amd64~~backup201407021638
# egrep '(vmlinuz|initrd)' /boot/grub/grub.cfg
linux /boot/vmlinuz-3.2.0-4-amd64 root=UUID=ff68c9e1-efea-4a2f-b011-f9d24a392b62 ro quiet
initrd /boot/initrd.img-3.2.0-4-amd64
linux /boot/vmlinuz-3.2.0-4-amd64~~backup201407021638 root=UUID=ff68c9e1-efea-4a2f-b011-f9d24a392b62 ro quiet
initrd /boot/initrd.img-3.2.0-4-amd64~~backup201407021638Again, the kernel version has been bumped to 3.2.57-3+deb7u2, but this time the old kernel image and initrd are backed up as ~~backup201407021638 files, alongside the new files.
The backup files are automatically picked up by update-grub and placed in grub.cfg.
Here’s how this looks in GRUB:
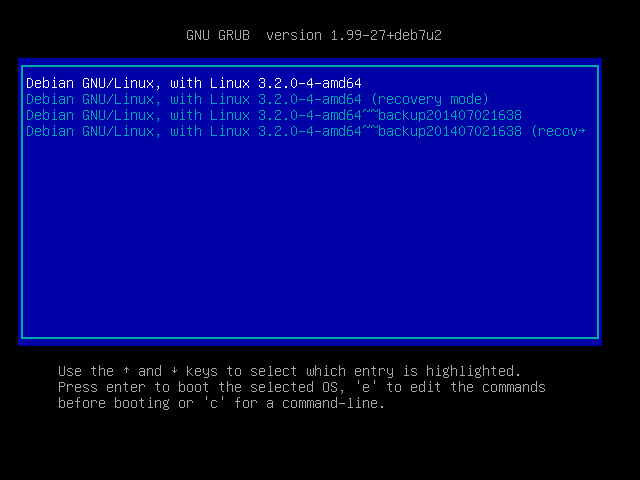
The tildes as version suffix look a bit ugly, but they are required to make sure the backups are sorted below the regular kernel image so it doesn’t boot as default. In Debian version numbers, a tilde counts as “lower” than any other character (see the Debian policy manual), so when GRUB sorts the kernel images newest-first, the non-backup kernels appear newer and go to the top of the list. Using the date as backup-versioning also ensures that the backups are sorted newest-first.
The problem with the snapshot machine
In the introduction, I mentioned that two of our machines failed to boot after a kernel update, but that the kernel update itself was not to blame. So, what happened?
This is a backup machine, keeping snapshots of a production application for a customer. It is a VM in Proxmox VE, with about 120GiB of storage, all allocated as a single root filesystem (and a small swap space). After the kernel update, GRUB exploded with “syntax error”s and “invalid command”s on boot, and manually trying to boot the kernel from the GRUB rescue shell resulted in “error: invalid magic number”. When booting from rescue media, everything seemed fine on inspection.
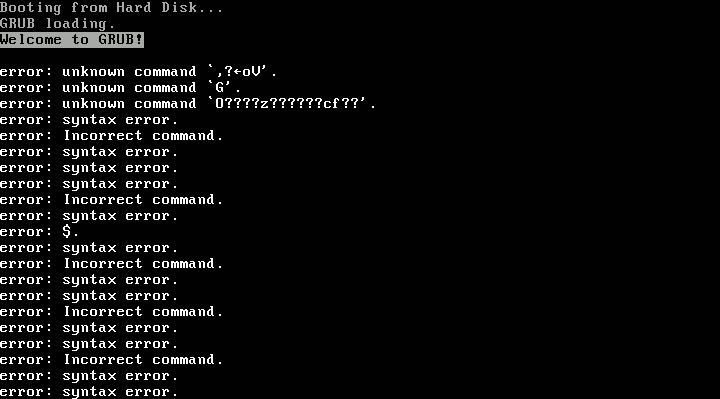
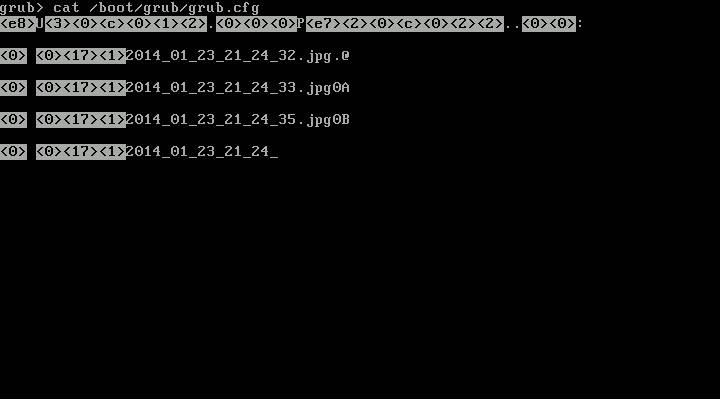
Why? Well, Linux accesses the disk by letting its SATA driver speak with the disk controller directly, using a linear addressing mode known as LBA48 to access up to 2^48 sectors (128PiB). This is fine. GRUB on the other hand, runs very early in the boot process and does not have SATA drivers or anything. Instead, it asks the BIOS to read some data from the disk for it. Typically this happens using a legacy addressing scheme known as CHS (cylinder-head-sector), in which the sector address to be read is split in three parts. This scheme has some limitations on the size of each of those three components, and the exact limits have changed over time.
This machine runs in a Proxmox VM, which uses KVM for its virtualization. Then I found this (emphasis mine):
Why these numbers? It’s a throwback to ancient technology: ye olde PC accessed disks using cylinder/head/sector technology, and the upper bounds on each bit are 16383, 16, 63. In my testing, KVM ignores the CHS settings in the disk image and assumes 16 heads/63 sectors, …
Aha. Assuming the number of cylinders is a 16-bit integer (a fairly common limitation), heads is 16 and sector count is 63, we get a limit of 2^16 * 16 * 63 = 66 060 288 addressable sectors, or exactly 31.5GiB. Some experimentation with moving the boot files around on the disk confirmed that with grub.cfg, the kernel image, and the initrd at 31GiB from the start of the disk, everything would work fine, but at 32GiB, GRUB would choke (probably reading the disk modulo 31.5GiB as the cylinder address overflowed). This was fixed by adding a separate /boot partition at the start of the disk, so everything GRUB needs is within the first GiB of the disk. Everything is happy again.
But, why did this only occur after a routine kernel update, when the machine had been running in production for months? That’s fairly easy to explain as well. When the machine was installed (and so when GRUB, the kernel image, and the initrd were first installed), the disk was still mostly empty. Most OSses tend to fill filesystems start-to-end, so all these files were allocated close to the start of the disk. Later, when the machine had been collecting snapshots for months, the disk had largely been filled up, only leaving space towards the end of the disk. The kernel update then installed a new kernel image, initrd and grub.cfg, all of which had to be allocated close to the end of the disk, beyond the 31.5GiB limit, inadvertently leaving the machine unbootable.
That won’t happen again because of the separate boot partition, and if it does, the kernel backups will help us get the machine back up quicker ;)
The problem with the gateway
That leaves the story of our network gateway, which suffered a similar (but completely unrelated) unexpected boot failure after the kernel update.
On this machine, GRUB was fine, it loaded the kernel and initrd without problems and booted them. But the initrd failed to find the root filesystem, and the system does really need that to finish booting. The machine is installed on a physical machine on a 2-disk Linux software RAID-1, and for some reason, the initrd refused to auto-start the RAID array.
It turned out there was a good reason for this.
Originally, the machine was named foo, but later we established a naming scheme and we renamed the machine to bar.
What I didn’t know is - md arrays have a name (as seen in the output of mdadm -D /dev/md0), and by default, this name is the hostname followed by a colon and a zero, foo:0 in this case.
The initrd autostarts arrays of the hostname:number format at boot.
Of course, since the hostname is now bar, the foo:0 array is ignored.
But wait, this only happened after a kernel update? Well yes. After the rename, the configration in the initrd still contained foo as hostname, so the old initrd would autostart foo:0 just fine. After the kernel update, the initrd was regenerated with the proper hostname bar, and it would no longer autostart foo:0. Oops.
This was fixed by renaming the array to bar:0, which was surprisingly tricky.
The only way to do this using mdadm is during the assemble action, which is only possible when the array has not yet been started.
This means it’s impossible to do this on a live system, as the root filesystem was on the array.
Luckily, it can be done from the failing initrd with mdadm --assemble /dev/md0 --update=name --name=bar:0 /dev/sd[ab]1.
This assembled the array, updating its name to bar:0.
After a reboot, the new initrd now boots fine.